序言
有的坑始终是要踩的,有的路始终是要走的
本次分享的是我在公司的一个真实线上事故,持续时长2小时,现分享出来供大家参考
线上mongodb架构
线上采用mongo副本集群的方式,总共3台机器,如下图:
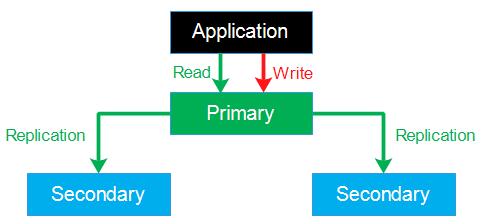
- 服务器为阿里云香港
- mongodb版本为3.2
- primary的priority设置为2
- 其他secondary的priority设置为1
事故现象
PHP抛异常,连接mongo出错。首先我猜测是网络原因导致php-fpm对mongo错误连接进行了缓存,在通知运维重启php-fpm后问题依旧。
登服务器后发现mongo集群3台机器挂掉了2台。
理论上来说,重新开启挂掉的mongo,集群在短时间内会自动恢复,但事实是mongo根本无法开启。
临时快速解决方案
事故后的状态:
- mongo集群短时间内无法恢复
- mongo集群3台机器中还有一台可用
基于以上现状,决定,为了保证线上服务立即可用,采取新开mongodb 2.6集群,导入原3.2集群数据的方式来恢复线上业务正常。
之所以采用新开2.6集群的办法,是由于以前的老业务在2.6集群中非常稳定,故为了保险起见使用2.6版本mongo。
日志分析
primary降级日志
提示找不到节点同步数据,并判定其中的一台secondary1为主:
xxxxT09:45:04.299+0800 I REPL [ReplicationExecutor] could not find member to sync from
xxxxT09:45:04.299+0800 I ASIO [ReplicationExecutor] dropping unhealthy pooled connection to ip:27017
xxxxT09:45:04.299+0800 I ASIO [ReplicationExecutor] after drop, pool was empty, going to spawn some connections
xxxxT09:45:04.299+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to ip:27017
xxxxT09:45:04.299+0800 I REPL [ReplicationExecutor] Member ip:27017 is now in state PRIMARY在若干毫秒后提示发现主节点,自动降级为从:
xxxxT09:45:04.316+0800 I NETWORK [initandlisten] connection accepted from ip:56865 #764865 (xx connections now open)
xxxxT09:45:04.318+0800 I REPL [ReplicationExecutor] stepping down from primary, because a new term has begun: 6
xxxxT09:45:04.319+0800 I NETWORK [initandlisten] connection accepted from ip:56866 #764866 (xx connections now open)
xxxxT09:45:04.325+0800 I REPL [replExecDBWorker-0] transition to SECONDARYsecondary升级日志
原从节点secondary1升级为主节点:
xxxxT09:45:05.320+0800 I REPL [rsSync] transition to primary complete; database writes are now permitted
xxxxT09:45:05.334+0800 I NETWORK [initandlisten] connection accepted from ip:11853 #762825 (xx connections now open)primary报错日志
原主节点在一次查询后报异常:
xxxxT09:45:05.526+0800 I COMMAND [conn764864] command as.api_log command: aggregate { query } keyUpdates:0 writeConflicts:0 numYields:7499 reslen:276 locks:{ Global: { acquireCount: { r: 15004 }, acquireWaitCount: { r: 1 }, timeAcquiringMicros: { r: 4097 } }, Database: { acquireCount: { r: 7502 } }, Collection: { acquireCount: { r: 7502 } } } protocol:op_query 169ms
xxxxT09:45:05.531+0800 I NETWORK [conn764864] SocketException handling request, closing client connection: 9001 socket exception [SEND_ERROR] server [ip:56862]
xxxxT09:45:05.550+0800 I REPL [ReplicationExecutor] Member ip:27017 is now in state PRIMARY
xxxxT09:45:05.550+0800 I REPL [ReplicationExecutor] Scheduling priority takeover at xxxxT09:45:15.550+0800
xxxxT09:45:05.622+0800 I REPL [ReplicationExecutor] syncing from: ip:27017
xxxxT09:45:05.629+0800 I REPL [SyncSourceFeedback] setting syncSourceFeedback to ip:27017
xxxxT09:45:05.635+0800 I ASIO [NetworkInterfaceASIO-BGSync-0] Connecting to ip:27017
xxxxT09:45:05.637+0800 I ASIO [NetworkInterfaceASIO-BGSync-0] Successfully connected to ip:27017
xxxxT09:45:05.646+0800 I NETWORK [conn708136] SocketException handling request, closing client connection: 9001 socket exception [SEND_ERROR] server [ip2:12811]conn708136和conn764864这两个连接都是在原主节点未降级时连接过来的。在原主节点降级后,这两个连接并未断开,并继续做一些查询操作,所以报通信异常。
后续整个集群有多次抢占主节点的现象,这样的链接错误也跟着多次出现。
primary抢占主节点
在若干秒后,原主节点日志信息表示此节点优先级更高,要把主节点接替回来:
xxxxT09:45:15.551+0800 I REPL [ReplicationExecutor] Starting an election for a priority takeover
xxxxT09:45:15.552+0800 I REPL [ReplicationExecutor] conducting a dry run election to see if we could be elected
xxxxT09:45:15.554+0800 I REPL [ReplicationExecutor] dry election run succeeded, running for election
xxxxT09:45:15.555+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to ip:27017
xxxxT09:45:15.556+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Successfully connected to ip:27017
xxxxT09:45:15.556+0800 I REPL [ReplicationExecutor] election succeeded, assuming primary role in term 7
xxxxT09:45:15.556+0800 I REPL [ReplicationExecutor] transition to PRIMARY
xxxxT09:45:15.557+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to ip2:27017
xxxxT09:45:15.557+0800 I REPL [rsSync] transition to primary complete; database writes are now permitted
xxxxT09:45:15.560+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Successfully connected to ip2:27017
xxxxT09:45:15.561+0800 I REPL [ReplicationExecutor] Member ip2:27017 is now in state SECONDARYsecondary降级日志
紧接着,另一个secondary收到主节点变动信息,新的主节点降级为从,同时关闭了所有连接:
xxxxT09:45:20.756+0800 I REPL [ReplicationExecutor] Starting an election, since we've seen no PRIMARY in the past 10000ms
xxxxT09:45:20.757+0800 I REPL [ReplicationExecutor] conducting a dry run election to see if we could be elected
xxxxT09:45:20.764+0800 I REPL [ReplicationExecutor] dry election run succeeded, running for election
xxxxT09:45:20.768+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to ip:27017
xxxxT09:45:20.768+0800 I REPL [ReplicationExecutor] could not find member to sync from
xxxxT09:45:20.769+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Successfully connected to ip:27017
xxxxT09:45:20.771+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to ip:27017
xxxxT09:45:20.771+0800 I REPL [ReplicationExecutor] election succeeded, assuming primary role in term 6
xxxxT09:45:20.771+0800 I REPL [ReplicationExecutor] transition to PRIMARY主节点抢占概况
- 最开始的主节点45分05秒就由主降为从
- 从节点1在45分20秒切换到主
- 中途45分15秒 原主节点 又把主抢回去了
- 中间频繁的状态切换,链接没有全部断开,出现通信异常
- 到46分01秒 抢回主的原主节点 再降为从,46分11秒再由于优先级高,抢回主
- 整个过程一直交替出现
- 最后mongo集群崩了
事故原因
间接原因
- mongo副本集配置有问题,3台机器的priority设置不一致
- 副本集没有增加仲裁节点
原主节点在副本集集群中priority级别比较高,每次都会竞争成主节点,会和前一个主节点的oplog进行对比并rollback。在故障时间1个小内发生过30次左右的频繁切换主从。最后回滚数据时两个节点同时挂掉,导致整个副本集状态强制降级为SECONDARY,最后仅剩的一个节点不可写。
直接原因
机器间内网网络出现波动,由于某一台机器的优先级比较高,内网网络波动导致这台机器的主不断被摘除和选举,一直不停切换,但3.2版本在切换了几次主从后,某些节点的进程会直接挂掉。我们通过禁用内网相关mongo端口访问模拟内网不稳定的情况重现了线上的这个问题。
模拟事故
模拟测试
对多个mongodb版本进行模拟网络异常测试。使用iptables进行断网、启动网络的循环测试,同时临时脚本在不停读取写入数据。
测试结果
- 2.6版本没问题,3.4版本没问题。3.2版本在循环断网10+次后出现错误oplog不同步导致集群挂掉
- 3.2的版本在某个mongo节点挂掉的情况下,副本集恢复稳定时间比2.6版本快很多
- 2.6的版本在某个mongo节点挂掉的情况下,无论是cli还是web下面连接mongo都有8秒左右的延迟,导致每个web请求会延迟8秒左右
解决方案
可能的最优解决方案
升级到3.4版本mongo,但不保证没有其他稳定性方面的问题。且需要从2.6升级到3.0到3.2到3.4的渐进升级方式。升级方式采用2.6副本集中加入3.0副本集节点,再摘除2.6副本集的方式,升级到3.2和3.4类似。
建议的解决方案
鉴于副本集节点挂掉的情况比较少见,并且在公司历史项目实践来看2.6版本mongo比较稳定,且不排除3.4版本是否有其他问题,决定使用以下方案解决:
- 2.6版本加入仲裁节点
- 加入某个mongo节点挂掉以及mongo副本集出现主从切换的监控
其他需要注意的点
- 各数据节点的优先级一定要一致,防止网络异常时主不停切换
- 所有节点个数是单数,因为可用节点要大于所有节点的1/2
- 关于主从节点的调研结果是:无法在副本集中加入主从,可用定时备份临时解决
- 做mongo副本集切换和副本集节点挂掉的监控
仲裁节点说明
- 仲裁节点的意义在于在出现选举投票无结果时,对选举结果直接产生影响。仲裁节点与数据节点不一样,他不保留数据内容,仅做选举仲裁。
- 至少需要加入2个仲裁节点,加仲裁节点操作对业务没有任何影响
- 2.6版本即使2个仲裁节点挂掉,也不会导致连接mongo的8秒左右延迟。也就是仅在数据节点挂掉的时候会导致2.6版本mongo连接延迟。
- 3个数据节点+2个仲裁节点,需要有至少3个节点存活,整个副本集才处于健康状态,也就是存活节点个数需要大于总节点数的一半。所以在加入2个仲裁节点后,允许整个集群挂掉2台机器。之前只有3个数据节点时是只允许挂掉1台。
如果您觉得您在我这里学到了新姿势,博主支持转载,姿势本身就是用来相互学习的。同时,本站文章如未注明均为 hisune 原创 请尊重劳动成果 转载请注明 转自: 记一次mongo线上事故 - hisune.com
1 Comments
123286473#225 Reply
学习~